Quando tengo dei seminari sull’accesso ai dati con Excel, una delle cose per me più interessanti è quando scopro modi diversi di fare le cose. La settimana scorsa, nel fare una tabella pivot basata su un elenco di Excel 2003, un allievo mi ha selezionato, nel passaggio 2 della creazione guidata, come intervallo dati non le celle dell’elenco, ma le intere colonne.
Esempio: partendo da un semplice elenco di 7 colonne per 38 righe, io avrei selezionato così:

Lui invece ha selezionato così:

Perché lo ha fatto? In questo modo, quando aggiunge nuove righe all’elenco, può aggiornare la pivot senza dover ridefinire l’intervallo. Interessante! Io invece devo ritornare ogni volta al passaggio 2 della creazione guidata e aggiungere le nuove righe.
Ci sono però dei lati negativi. Si risolve il problema dell’aggiornamento ma se ne creano altri:
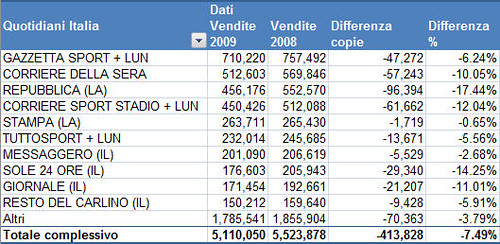
- La dimensione del file: un elenco di 20KB a cui si aggiunge una pivot fatta nel primo modo, rimane di 20KB; nel secondo modo diventa un file di 900KB (un elenco di 56KB diventa un file di 2MB!).
- Gli aggiornamenti: diventano leeenti, e visto che la pivot viene aggiornata anche all’apertura, anche aprire il file diventa leeento.
- Nel costruire la pivot, il campo dei totali non viene sommato ma contato, a causa della presenza di celle vuote nella colonna.
- Sui campi di data, non si riesce ad aggregare per mese/anno, sempre a causa delle celle vuote.
Morale della favola: preferisco il mio modo.
Se invece tu hai un modo ancora diverso di fare questa cosa, sono interessatissimo a conoscerlo: fammi sapere.